背景
虽然计算机的发展历史也就短短的几十年,但计算机计算的发展却非常迅速,特别是现在已经出现了几十核的CPU![]() ,但芯片的时钟频率目前已是非常难以提升,芯片厂商也只有发展多核这条路了。对于程序员来说,如何在多核情况下充分利用好硬件资源写出能够“正确”的代码就显的尤为重要。
,但芯片的时钟频率目前已是非常难以提升,芯片厂商也只有发展多核这条路了。对于程序员来说,如何在多核情况下充分利用好硬件资源写出能够“正确”的代码就显的尤为重要。
Java内存模型就是教人如果在并发编程的情况下写出“正确”的代码。导致程序员可能写出“不正确”的代码的因素很多,如编译器的优化、CPU高速缓存优化等。这些优化有些是软件实现的,有些是硬件实现的,而Java内存模型是通过一个抽象模型(用来屏蔽软件或硬件的具体实现)指导程序员写出并发“正确”的代码。
种类繁多的微架构
| 微架构 | 设计 | 说明 | |
|---|---|---|---|
| X86 | CISC | IA32 ➟ AMD64 ➟ Intel64 | |
| IA64 | EPIC | IntelHP | |
| ARM | RISC | Advanced RISC Machine | |
| Power PC | RISC | Apple–IBM–Motorola alliance | |
| ALPHA | RISC | … | |
| PA-RISC | RISC | … | |
| … | |||
EPIC相关介绍: Itanium 处理器系列的 EPIC 架构
多线程(并行)编程
对于传统的单核处理器来说微架构层面不存在可见性的问题,因为因为CPU仅拥有一套高速缓存,不同线程不可能因此读到不同值。
并发和并行的区别就是一个处理器同时处理多个任务和多个处理器或者是多核的处理器同时处理多个不同的任务。前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生:
- 并发性(concurrency),又称共行性,是指能处理多个同时性活动的能力,并发事件之间不一定要同一时刻发生。
- 并行(parallelism)是指同时发生的两个并发事件,具有并发的含义,而并发则不一定并行。
来个比喻:并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头。
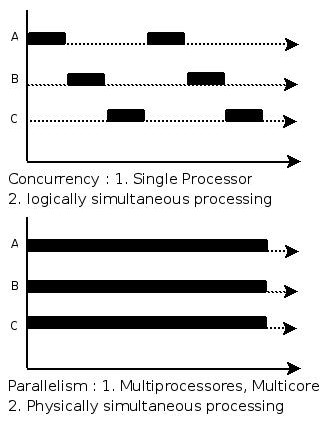
图片引用自:http://www.cnblogs.com/NickyYe/archive/2008/12/01/1344802.html
线程间并行运行的问题举例会在“微架构优化举例”中提到。
编译器优化举例
下面是一个C#![]() 的关于
的关于volatile![]() 的例子:
的例子:
class Test
{
private bool _loop = true;
public static void Main()
{
Test test1 = new Test();
// Set _loop to false on another thread
new Thread(() => { test1._loop = false;}).Start();
// Poll the _loop field until it is set to false
while (test1._loop == true) ;
// The loop above will never terminate!
}
}
请看以下循环代码:
while (test1._loop == true) ;
但有可能实现上运行如下的代码:
if (test1._loop) { while (true); }
即等同于编译后的循环代码汇编如下:
00000068 test eax,eax
0000006a jne 00000068
如果将_loop![]() 变量标记为
变量标记为volatile![]() ,那么生成的代码如下:
,那么生成的代码如下:
00000064 cmp byte ptr [eax+4],0
00000068 jne 00000064
从上面的例子我们可以看到当一个变量是否标记为volatile![]() 会影响编译器生成的代码是否访问“缓存”(寄存器),因为访问寄存器快于L1,且远远快于内存访问。
会影响编译器生成的代码是否访问“缓存”(寄存器),因为访问寄存器快于L1,且远远快于内存访问。
代码引用自:http://igoro.com/archive/volatile-keyword-in-c-memory-model-explained/
微架构优化举例
x86![]() 和
和x64![]() (
(x86_64![]() )实现了强一致的内存模型,即所有的内存访问都已经是
)实现了强一致的内存模型,即所有的内存访问都已经是volatile![]() 的。所以
的。所以volatile![]() 的字段会强制编译器避免做了些高级优化,如在一个循环中读写一个变量,生成的代码将会是一个非
的字段会强制编译器避免做了些高级优化,如在一个循环中读写一个变量,生成的代码将会是一个非volatile![]() 的内存读(这种方式已经在上面举例说明)。
的内存读(这种方式已经在上面举例说明)。
然而,安腾处理器实现了一个弱的内存模型。对于目标处理器如果是安腾的话,对于volatile![]() 内存访问编译器需要使用一些特别的指令:
内存访问编译器需要使用一些特别的指令:ld.acq![]() 和
和st.red![]() 替代
替代ld![]() 和
和st![]() 。指令
。指令ld.acq![]() 的意思是说“请先刷新缓存并读入该值”,而指令
的意思是说“请先刷新缓存并读入该值”,而指令st.rel![]() 是说“把值写入缓存,并将这个值刷新到主内存”。而
是说“把值写入缓存,并将这个值刷新到主内存”。而ld![]() 和
和st![]() 指令仅访问处理器的缓存,而这个缓存对于别的处理器可能是不可见的。
指令仅访问处理器的缓存,而这个缓存对于别的处理器可能是不可见的。
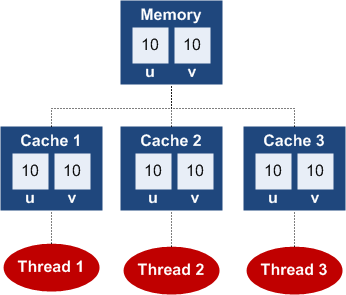
下面我们看一下图例:
1. 初始状态
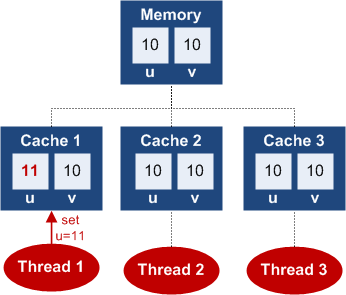
2. 普通写
对于非volatile![]() 的写数据有可能是仅仅更新的当前线程所在处理器的缓存,而未更新该值到主内存中:
的写数据有可能是仅仅更新的当前线程所在处理器的缓存,而未更新该值到主内存中:
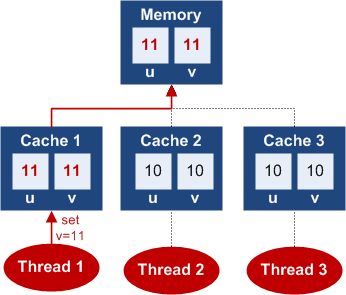
3. volatile 写
写
对于volatile![]() 写数据将会先写入当前线程所有处理器的缓存,然后即将对应的缓存数据刷新到主内存中。如,我们将字段
写数据将会先写入当前线程所有处理器的缓存,然后即将对应的缓存数据刷新到主内存中。如,我们将字段v![]() 设置为
设置为11![]() ,那么变量值
,那么变量值u![]() 、
、v![]() 都会被刷新到主内存中:
都会被刷新到主内存中:
4. 普通读
通常来说,对于非volatile![]() 读则仅从当前线程所在处理器的缓存读入值,而不是从主内存中。所以,即便线程1将
读则仅从当前线程所在处理器的缓存读入值,而不是从主内存中。所以,即便线程1将u![]() 设置为
设置为11![]() ,而线程2在读
,而线程2在读u![]() 时,他也将只能读到
时,他也将只能读到10![]() 。
。
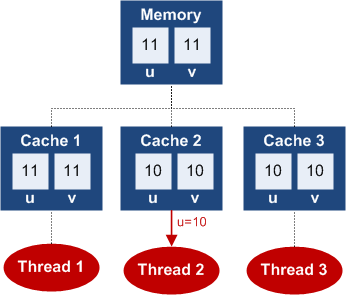
5. volatile读
最后,我们看一个volatile![]() 读的例子。线程2通过
读的例子。线程2通过volatile![]() 读到字段
读到字段v![]() 的最新值:
的最新值:
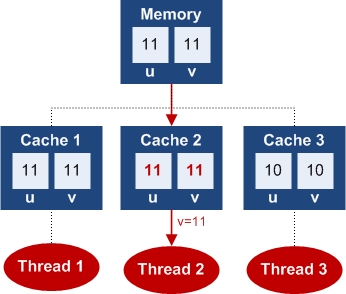
图片引用自:http://igoro.com/archive/volatile-keyword-in-c-memory-model-explained/
微架构之x86
x86![]() 是一个指令集架构家族,最早由英特尔在
是一个指令集架构家族,最早由英特尔在Intel 8086![]() CPU上开发出来。该系列较早期的处理器名称是以数字来表示
CPU上开发出来。该系列较早期的处理器名称是以数字来表示80x86![]() 。由于以
。由于以86![]() 作为结尾,包括
作为结尾,包括Intel 8086![]() 、
、80186![]() 、
、80286![]() 、
、80386![]() 以及
以及80486![]() ,因此其架构被称为
,因此其架构被称为x86![]() 。
。
发展历程
x86![]() 架构于
架构于1978年![]() 推出的
推出的Intel 8086![]() 中央处理器中首度出现,它是从
中央处理器中首度出现,它是从Intel 8008![]() 处理器中发展而来的,而
处理器中发展而来的,而8008![]() 则是发展自
则是发展自Intel 4004![]() 的。
的。8086![]() 在三年后为
在三年后为IBM PC![]() 所选用,之后x86便成为了个人计算机的标准平台,成为了历来最成功的CPU架构。
所选用,之后x86便成为了个人计算机的标准平台,成为了历来最成功的CPU架构。
8086![]() 是
是16位![]() 处理器;直到
处理器;直到1985年![]()
32位![]() 的
的80386![]() 的开发,这个架构都维持是
的开发,这个架构都维持是16位![]() 。接着一系列的处理器表示了
。接着一系列的处理器表示了32位![]() 架构的细微改进,推出了数种的扩充,直到
架构的细微改进,推出了数种的扩充,直到2003年![]()
AMD![]() 对于这个架构发展了
对于这个架构发展了64位![]() 的扩充,并命名为
的扩充,并命名为AMD64![]() 。后来英特尔也推出了与之兼容的处理器,并命名为
。后来英特尔也推出了与之兼容的处理器,并命名为Intel 64![]() 。两者一般被统称为
。两者一般被统称为x86-64![]() 或
或x64![]() ,开创了
,开创了x86![]() 的
的64位![]() 时代。
时代。
英特尔在1990年代![]() 就与惠普合作提出了一种用在安腾系列处理器中的独立的
就与惠普合作提出了一种用在安腾系列处理器中的独立的64位![]() 架构,这种架构被称为
架构,这种架构被称为IA-64![]() 。与
。与x86![]() 架构的
架构的IA-32![]() 不同,
不同,IA-64![]() 是一种崭新的系统,和x86架构完全没有相似性;不应该把它与
是一种崭新的系统,和x86架构完全没有相似性;不应该把它与x86-64![]() 或
或x64![]() 弄混。
弄混。
CPU缓存
Core 2 L1 Cache(容量32K,8路,缓存线64字节):
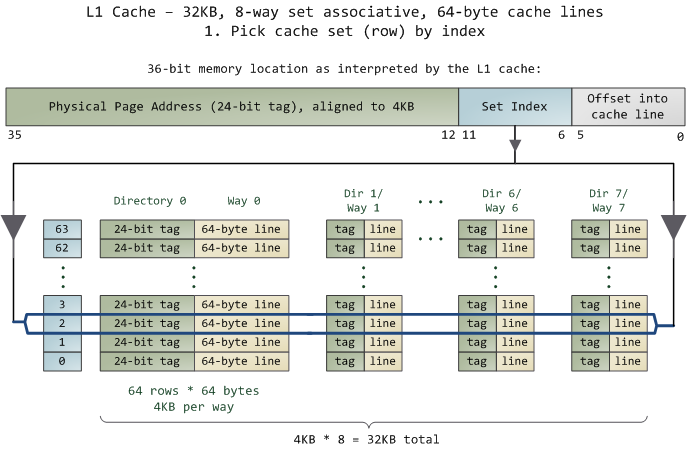
图片引用自:http://duartes.org/gustavo/blog/post/intel-cpu-caches
高速缓存L1,L2及L3的结构:

在Linux下查看高速缓存的信息:
cat /sys/devices/system/cpu/cpu{N}/cache/index{N}/{?} | |
|---|---|
| level | 123L1L2L3 |
| type | DataInstructionL1Instruction |
| coherency_line_size | 缓存线Cache Line |
| number_of_sets | 是多少行 |
| ways_of_associativity | 一共有多少路 |
| size | 32K== coherency_line_size * number_of_sets * ways_of_associativity |
| shared_cpu_list | 在哪几个“CPU |
| shared_cpu_map | 在哪几个“CPU |
缓存一致性
在x86![]() 微架构下,高速缓存是保证一致性的,即只要程序读写内存地址即可保证一定是读到的最新值,且写入的值可被读到。这种一致性通过缓存一致性协议实现。
微架构下,高速缓存是保证一致性的,即只要程序读写内存地址即可保证一定是读到的最新值,且写入的值可被读到。这种一致性通过缓存一致性协议实现。
缓存一致性(MESI![]() ,
, Modified Exclusive Shared Invalid![]() )协议,也称为伊利诺伊协议(
)协议,也称为伊利诺伊协议(Illinois protocol![]() ,由伊利诺伊大学香槟[
,由伊利诺伊大学香槟[Urbana-Champaign![]() ]分校开发),被广泛用于缓存一致性和内存一致性。是支持缓存回写的最通用的一种协议。
]分校开发),被广泛用于缓存一致性和内存一致性。是支持缓存回写的最通用的一种协议。
在MESI![]() 协议中,每个缓存行有4个状态,可用2个bit表示,它们分别是:
协议中,每个缓存行有4个状态,可用2个bit表示,它们分别是:
| 状态 | 描述 |
|---|---|
| M(Modified) | 这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache |
| E(Exclusive) | 这行数据有效,数据和内存中的数据一致,数据只存在于本Cache |
| S(Shared) | 这行数据有效,数据和内存中的数据一致,数据存在于很多Cache |
| I(Invalid) | 这行数据无效 |
MESI![]() 状态迁移图:
状态迁移图:
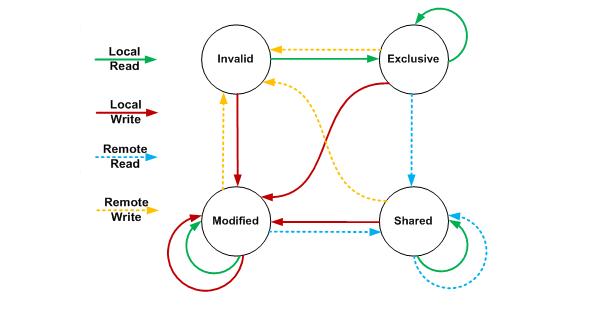
伪共享(False Sharing)
伪共享![]() 是在多核CPU下才会出现的一种特殊的竞争访问内存的情况,即当两个在一个缓存线中的变量在被两个线程频繁修改的时候会出现大量
是在多核CPU下才会出现的一种特殊的竞争访问内存的情况,即当两个在一个缓存线中的变量在被两个线程频繁修改的时候会出现大量L1![]() ,
, L1 L2![]() 或
或L1 L2 L3![]() 缓存失效。
缓存失效。
伪共享原理介绍:
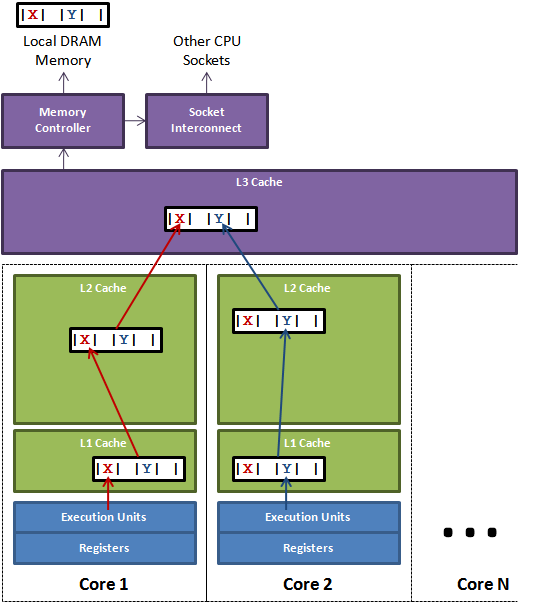
测试伪共享的代码:
public final class FalseSharing
implements Runnable
{
public final static int NUM_THREADS = 4; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];
static
{
for (int i = 0; i < longs.length; i++)
{
longs[i] = new VolatileLong();
}
}
public FalseSharing(final int arrayIndex)
{
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception
{
final long start = System.nanoTime();
runTest();
System.out.println("duration = " + (System.nanoTime() - start));
}
private static void runTest() throws InterruptedException
{
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++)
{
threads[i] = new Thread(new FalseSharing(i));
}
for (Thread t : threads)
{
t.start();
}
for (Thread t : threads)
{
t.join();
}
}
public void run()
{
long i = ITERATIONS + 1;
while (0 != --i)
{
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
}
伪共享是否做padding的测试结果:
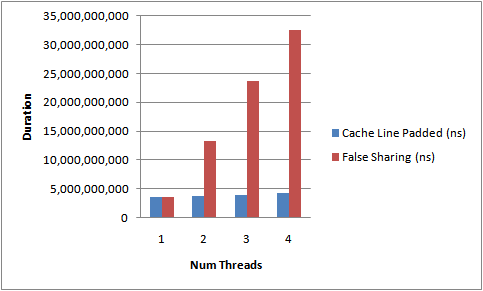
图片及代码引用自:http://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html
指令重排
我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多。当CPU的计算速度远远超过访问cache时,会产生cache wait,过多的cache wait就会造成性能瓶颈。
针对这种情况,多数架构(包括X86)采用了一种将cache分片的解决方案,即将一块cache划分成互不关联地多个 slots (逻辑存储单元,又名 Memory Bank 或 Cache Bank),CPU可以自行选择在多个idle bank中进行存取。这种SMP的设计,显著提高了CPU的并行处理能力,也回避了cache访问瓶颈。
Memory Bank的划分:
- 一般 Memory bank 是按cache address来划分的。比如 偶数adress 0×12345000 分到 bank 0, 奇数address 0×12345100 分到 bank1。
重排序的种类:
- 编译期重排:编译源代码时,编译器依据对上下文的分析,对指令进行重排序,以之更适合于CPU的并行执行。
- 运行期重排:CPU在执行过程中,动态分析依赖部件的效能,对指令做重排序优化。
多处理器(含多核和超线程)系统中的指令重排遵循以下规则:
- Individual processors use the same ordering principles as in a single-processor system.
- Writes by a single processor are observed in the same order by all processors.
- Writes from an individual processor are NOT ordered with respect to the writes from other processors.
- Memory ordering obeys causality (memory ordering respects transitive visibility).
- Any two stores are seen in a consistent order by processors other than those performing the stores
- Locked instructions have a total order.
x86![]() 指令重排详见:
指令重排详见:8.2 MEMORY ORDERING![]() : Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A: System Programming Guide, Part 1
: Intel® 64 and IA-32 Architectures Software Developer’s Manual, Volume 3A: System Programming Guide, Part 1
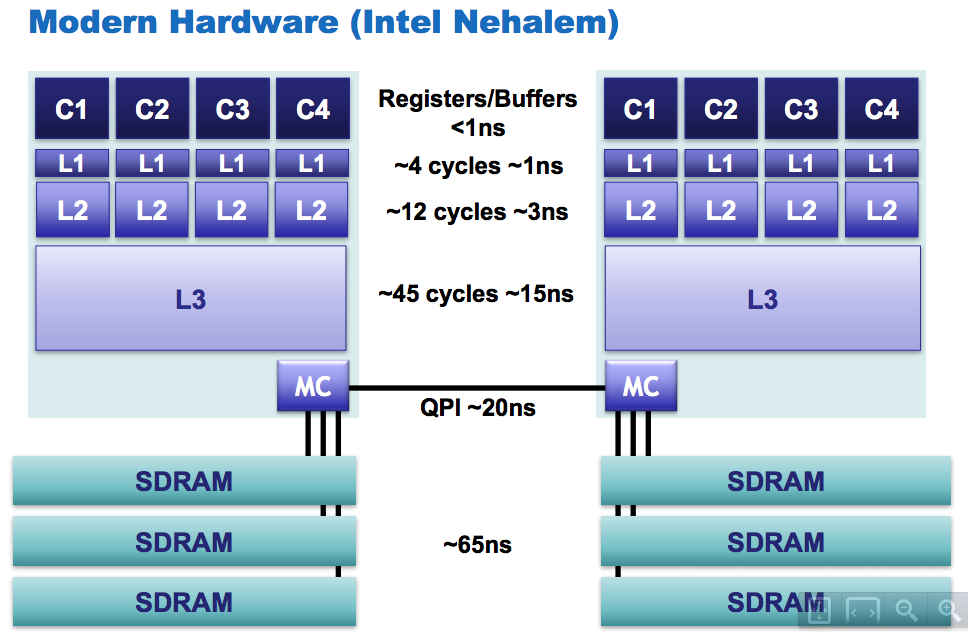
CPU访问相关性能
Java内存模型
我们先来看一段代码:
final class SetCheck {
private int a = 0;
private long b = 0;
void set() {
a = 1;
b = -1;
}
boolean check() {
return ((b == 0) ||
(b == -1 && a == 1));
}
}
代码引用自:http://gee.cs.oswego.edu/dl/cpj/jmm.html
逻辑上来讲,因为a = 1![]() 早于
早于b = -1![]() ,所以
,所以check()![]() 函数返回必定为
函数返回必定为true![]() ,但实际情况却未必如此,在某些特殊的场景下(如并发场景下在特殊的微架构平台上)可能会返回
,但实际情况却未必如此,在某些特殊的场景下(如并发场景下在特殊的微架构平台上)可能会返回false![]() 。需要解决这一类问题,Java才引入了Java内存模型。
。需要解决这一类问题,Java才引入了Java内存模型。
内存模型
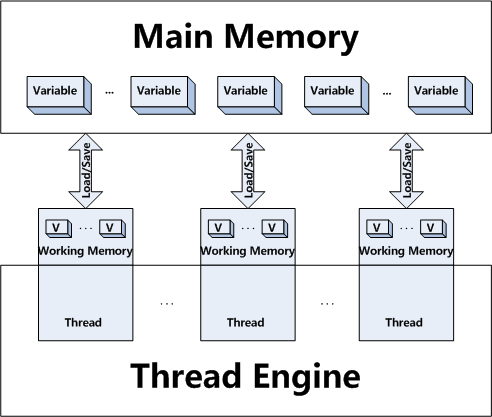
原子性
某些指令的执行是需要有不可分割的效果的(执行不可打断)。为了这样的模型,该规则仅用于简单的读、写内存单元,包含了实例及静态字段(当然也包含数组元素),但不包含在函数中的局部变量。
可见性
在一个线程写入变量后另外一个线程需要对该变化可见。效果是当一个线程写入一个字段后,另外一个线程需要对这个字段可见(写入的最新值)。
happen-before
- 同一个线程中的每个
Actionhappens-beforeAction- 对一个监视器的解锁
happens-before- 对
volatilehappens-beforeThread.start()happens-beforeThreadhappens-beforeThread.join()Thread.isAlive()==false- 一个线程
Ainterrupt()happens-beforeABABABisInterrupted()> interrupted()- 一个对象构造函数的结束
happens-beforefinalizer- 如果A动作
happens-beforeBhappens-beforeCAhappens-beforeC
重排序
任意一个线程都可能表现的乱序执行。而排序问题也总是围绕赋值语句的读、写顺序。
final
一个对象的final![]() 字段值是在它的构造方法里面设置的。假设对象被正确的构造了,一旦对象被构造,在构造方法里面设置给
字段值是在它的构造方法里面设置的。假设对象被正确的构造了,一旦对象被构造,在构造方法里面设置给final![]() 字段的的值在没有同步的情况下对所有其他的线程都会可见。另外,引用这些
字段的的值在没有同步的情况下对所有其他的线程都会可见。另外,引用这些final![]() 字段的对象或数组都将会看到
字段的对象或数组都将会看到final![]() 字段的最新值。
字段的最新值。
class FinalFieldExample {
final int x;
int y;
static FinalFieldExample f;
public FinalFieldExample() {
x = 3;
y = 4;
}
static void writer() {
f = new FinalFieldExample();
}
static void reader() {
if (f != null) {
int i = f.x; // <---- 能读到x的正确值:3
int j = f.y; // <---- 不一定能读到y的正确值:4
}
}
}
public FinalFieldExample() { // bad!
x = 3;
y = 4;
// bad construction - allowing this to escape
global.obj = this; // <---- 在这里外部程序也未必能够看到x的正确值:3
}
代码引用自:http://www.cs.umd.edu/~pugh/java/memoryModel/jsr-133-faq.html
volatile
volatile![]() 关键词是告诉编译器说“这个变量是易变的,请保证始终读、写唯一的值,并且请保证原子性”,当编译器接收到这些信息后,编译器会做如下处理:
关键词是告诉编译器说“这个变量是易变的,请保证始终读、写唯一的值,并且请保证原子性”,当编译器接收到这些信息后,编译器会做如下处理:
- 禁止编译器本身对该变量的读、写缓存优化
- 根据当前的微架构,在生成读、写该变量的硬件指令时禁止CPU的高速缓存
X86:微架构已经保证了缓存的强一致性,无须使用特别的指令IA64:使用ld.acq或st.rel指令进行读、写,保证CPU的高速缓存被更新
- 禁止对这个变量读写前后的指令重排
X86:mfence or cpuid or locked insn (lock; addl $0,0(%%esp))IA64:mf
对于原子性、可见性和重排序来说,定义一个volatile![]() 的字段的作用等价于下面这样的类(定义一个
的字段的作用等价于下面这样的类(定义一个synchronized![]() 保护的使用
保护的使用get![]() /
/set![]() 方法访问的类):
方法访问的类):
final class VFloat {
private float value;
final synchronized void set(float f) { value = f; }
final synchronized float get() { return value; }
}
代码引用自:http://gee.cs.oswego.edu/dl/cpj/jmm.html
synchronized
synchronized![]() 的锁原理及优化详见:Study_Java_HotSpot_Concurrent
的锁原理及优化详见:Study_Java_HotSpot_Concurrent
@Contended
sun.misc.Contended![]()
@Contended![]() 通过JEP 142 (在特定字段上减少高速缓存竞争访问)引入,即针对伪共享提供一种解决方案,解决方法是通过
通过JEP 142 (在特定字段上减少高速缓存竞争访问)引入,即针对伪共享提供一种解决方案,解决方法是通过@Contended![]() 来标记哪些字段是竞争访问的,编译器在编译的时候即将存在竞争访问的字段对齐到不同的缓存线。
来标记哪些字段是竞争访问的,编译器在编译的时候即将存在竞争访问的字段对齐到不同的缓存线。
Sample代码jdk/src/share/classes/java/lang/Thread.java![]() :
:
2034 // The following three initially uninitialized fields are exclusively
2035 // managed by class java.util.concurrent.ThreadLocalRandom. Additionally,
2036 // these fields are isolated from other fields in Thread due to being
2037 // heavily updated.
2038 /** The current seed for a ThreadLocalRandom */
2039 @sun.misc.Contended("tlr")
2040 long threadLocalRandomSeed;
2041 /** Probe hash value; nonzero if threadLocalRandomSeed initialized */
2042 @sun.misc.Contended("tlr")
2043 int threadLocalRandomProbe;
2044 /** Secondary seed isolated from public ThreadLocalRandom sequence */
2045 @sun.misc.Contended("tlr")
2046 int threadLocalRandomSecondarySeed;
代码分析
对于Java内存模型主要就是多线程编程下面是否功能正常工作,所以我们这里看看几段代码吧。
Sample 1
源代码:
public class Sample {
private static int count = 0;
public static void increment() {
count++;
}
}
这个代码线程安全么?为什么?
Sample 2
源代码:
// 代码1
public class Sample {
private static int count = 0;
synchronized public static void increment() {
count++;
}
}
// 代码2
public class Sample {
private static AtomicInteger count = new AtomicInteger(0);
public static void increment() {
count.getAndIncrement();
}
}
上面两段代码其实也是悲观锁和乐观锁的盒子,synchronized![]() 需要先取得锁,而
需要先取得锁,而getAndIncrement![]() 则使用
则使用lock cmpxchg![]() 或
或lock xadd![]() 完成,当使用
完成,当使用lock cmpxchg![]() 则相当于乐观锁,最后
则相当于乐观锁,最后lock xadd![]() 相当于在更新数据库的时候直接执行
相当于在更新数据库的时候直接执行update set value=value+1 where id=?![]() 。
。
Sample 3
源代码:
public class CacheTest {
public static void main(String[] args) {
int[] arr = new int[64 * 1024 * 1024];
for (int _loop = 0; _loop < 10; _loop++) {
System.out.print("Round: " + _loop);
{
long s = System.currentTimeMillis();
for (int i = 0; i < arr.length; i++) {
arr[i] *= 3;
}
System.out.print("\t" + (System.currentTimeMillis() - s) + " ms");
}
{
long s = System.currentTimeMillis();
for (int i = 0; i < arr.length; i += 8) {
arr[i] *= 3;
}
System.out.print("\t" + (System.currentTimeMillis() - s) + " ms");
}
{
long s = System.currentTimeMillis();
for (int i = 0; i < arr.length; i += 16) {
arr[i] *= 3;
}
System.out.print("\t" + (System.currentTimeMillis() - s) + " ms");
}
{
long s = System.currentTimeMillis();
for (int i = 0; i < arr.length; i += 32) {
arr[i] *= 3;
}
System.out.print("\t" + (System.currentTimeMillis() - s) + " ms");
}
System.out.println();
}
}
}
测试结果如下:
从下面的结果可以看到只有到了第4列消耗的时间大幅减少(测试数据在我的MBP上得到)。为什么呢?
Round: 0 164 ms 135 ms 132 ms 90 ms
Round: 1 169 ms 136 ms 147 ms 103 ms
Round: 2 140 ms 131 ms 131 ms 83 ms
Round: 3 141 ms 131 ms 133 ms 82 ms
Round: 4 165 ms 140 ms 134 ms 84 ms
Round: 5 172 ms 135 ms 129 ms 89 ms
Round: 6 143 ms 149 ms 129 ms 93 ms
Round: 7 140 ms 136 ms 130 ms 88 ms
Round: 8 137 ms 136 ms 129 ms 86 ms
Round: 9 137 ms 131 ms 132 ms 82 ms
K与响应时间的关系:
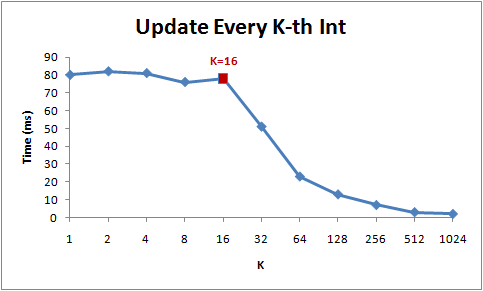
图片及代码引用自:http://igoro.com/archive/gallery-of-processor-cache-effects/
参考资料
- JSR 133: JavaTM Memory Model and Thread Specification Revision
- JSR 133 (Java Memory Model) FAQ
- The JSR-133 Cookbook for Compiler Writers
- Java内存模型FAQ
- Memory ordering
- Itanium
- 显式并行指令运算(EPIC)
- DEC Alpha
- PA-RISC
- The Java® Language Specification Java SE 7 Edition
- The Java® Virtual Machine Specification Java SE 7 Edition
- Synchronization and the Java Memory Model
- Common Language Infrastructure (CLI)
- CLR Memory Model
- Volatile reads and writes, and timeliness
- Memory Model
- CLR 2.0 memory model
- Understand the Impact of Low-Lock Techniques in Multithreaded Apps
- Volatile keyword in C# – memory model explained
- The Go Memory Model
- Cache: a place for concealment and safekeeping
- Cache:一个隐藏并保管数据的场所
- x86
- Study_CPU_MESI
- Study_Java_HotSpot_Concurrent
- Java @Contended annotation to help reduce false sharing
- JEP 142: Reduce Cache Contention on Specified Fields
- PowerPC
- ARM架构
- ARM Holdings
- 并发和并行的区别:吃馒头的比喻
- False Sharing
- happens-before规则和指令重排
- Intel® 64 and IA-32 Architectures Software Developer Manuals